当大模型参数竞赛进入瓶颈期,硅谷AI圈正在悄然完成一场“看不见的革命”。这场革命的主角不是更强的模型,而是一套让AI从“实验室玩具”真正走向“生产线工具”的工程化体系——Harness Engineering(驾驭工程)。本文将从零开始,带你全面拆解这个2026年最硬核的AI工程化概念。
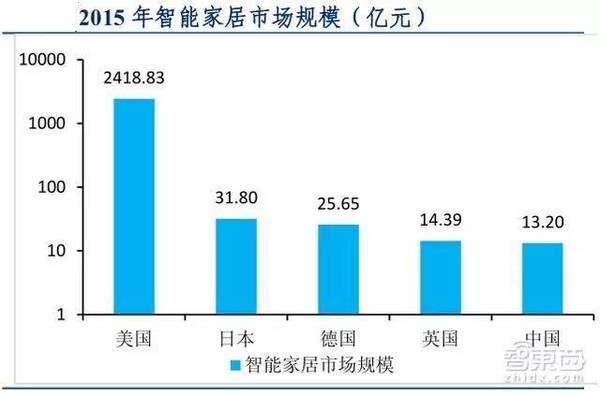
2026年4月10日,距Mitchell Hashimoto正式提出Harness Engineering术语已过去两个月,硅谷AI人工助手领域正经历着深刻的技术范式转移。据Anthropic与研究机构Material对500多位美国技术领导者的调研显示,81%的组织计划在2026年涉足更复杂的AI智能体使用场景-1。一个被反复验证的事实逐渐浮出水面:Agent的能力瓶颈不在模型本身,而在模型运行的“环境” 。Harness Engineering(驾驭工程)正是为了解决这一问题而诞生,它代表着一套围绕AI Agent构建的生产级运行时基础设施与工程化范式,被OpenAI、Anthropic、LangChain等头部厂商定义为“AI从对话框走向生产力的关键架构”-7。
一、痛点切入:为什么传统Agent框架“能做demo却无法稳定落地”?
在理解Harness Engineering之前,我们先来看传统AI Agent框架在实际生产中暴露的几大痛点:
典型场景:假设你正在开发一个能自动处理客户工单的AI助手。在演示Demo中,它表现完美——用户说“帮我查一下订单状态”,AI调用API返回结果。但当你在生产环境跑了一个月后,问题开始批量出现:
传统实现方式(以伪代码示意):
传统Agent的核心逻辑——过于依赖模型自身 def agent_run(user_input): 只有:模型推理 + 工具调用 plan = llm.reason(user_input) 模型生成执行计划 result = execute_tool(plan.tool) 调用工具 return llm.summarize(result) 模型总结输出 没有:状态管理、纠错机制、安全检查、运行约束
痛点逐一拆解:
任务路径坍塌(Task Path Collapse) :随着步骤增加,模型每一步产生的细微偏差会累积,最终导致任务失败。就像从A到B走一条长路,每一步偏1度,最终差之千里-25。
上下文稀释:长时任务中,AI容易出现“注意力稀释”——上下文窗口被大量历史信息塞满,关键信号的权重被稀释,导致步骤失控。举个例子,给Agent提供1000页的说明文档,效果反而不如一张精准的“索引地图”-7。
缺乏纠错机制:AI可能反复犯同一类错误,却没有自动修正的能力。生产环境中API超时、权限异常、数据错误会直接导致任务崩溃-7。
可解释性不足:企业级场景中Agent输出不可审计、存在幻觉,无法满足安全与监管要求-7。
工具开销不可控:一个包含175个工具的MCP服务器,仅工具定义就可能消耗26%的上下文预算,严重影响Agent性能-7。
这些痛点的根源在于:传统Agent框架(LangGraph、AutoGPT、CrewAI等)只解决了“开发时”问题——告诉开发者“怎么把Agent造出来”,但完全没有解决“运行时”的稳定性与可控性问题-7。2026年,AI Agent的落地不再是算法的竞赛,而是工程确定性的竞赛-25。
二、核心概念:Harness Engineering(驾驭工程)
定义:Harness Engineering(驾驭工程)是为大语言模型(LLM,Large Language Model)及AI Agent构建模型之外的全量运行管控系统,通过工程化手段实现对AI行为的约束、校验、执行、记忆、安全管控与错误自愈-6。
通俗理解:如果把大模型比作一位知识渊博但容易“走神”的天才员工,那么Harness就是为这位天才搭建的“办公环境+工作流程+监督机制”——
没有Harness:天才员工自由发挥,可能天马行空跑偏,也可能卡在某个问题上反复纠结;
有了Harness:划定工作范围、设定工作流程、安装监控面板、配备纠错助手,让天才员工既发挥能力,又不“出格”。
核心公式:
Agent = Model + HarnessModel代表LLM(如GPT、Claude、Gemini等),提供核心的推理、规划、决策能力,是Agent的“智能本体”;Harness则包含模型之外的全部代码、环境、规则、调度、验证体系,是Agent的“执行与控制系统”-6。LangChain工程师Vivek Trivedy的精炼定义一语道破:“如果你不是模型,你就是Harness。”-6
三、关联概念:从RAG到Agent到MCP的技术演进
要理解Harness Engineering,需要先理清它与几个核心概念的逻辑关系。
RAG(Retrieval-Augmented Generation,检索增强生成) :RAG的核心思想是“先检索,再生成”。当用户提问时,系统先在知识库中检索相关文档,将检索结果嵌入提示词,再交给模型生成最终回答-11。它让模型具备了实时知识访问能力,但本质上仍是“被动问答”型的智能-11。
Agent(智能体) :如果说RAG让模型“知道”,那么Agent让模型“能做”。Agent是能自主感知、思考、行动的任务执行体,通常具备记忆能力、工具调用能力、任务规划和自我反思能力-11。
MCP(Model Context Protocol,模型上下文协议) :由OpenAI推出的统一协议标准,用于规范模型与外部系统的交互方式。可以理解为“AI世界的操作系统API”-11。
三者关系:可以用一句话概括——RAG解决“知识不够”的问题,Agent解决“行动不够”的问题,MCP解决“协同不够”的问题。三者构成了新一代AI应用的分层架构-11。
与Harness Engineering的关系:Harness Engineering是更高维度的概念。如果把Agent看作“智能体”,那么Harness就是让这个智能体能够在企业生产环境中稳定运行的“工程化底座”。LangChain的实测数据印证了这一理念的重要性:仅优化Harness层的逻辑,在底层模型完全不变的情况下,Coding Agent的任务得分从52.8提升至66.5,行业排名从第30名跃升至第5名-7。
四、代码示例:从零构建一个带Harness的AI助手
下面我们用Python展示一个带基础Harness架构的AI助手核心逻辑。注意,这是一个极简版示例,主要用于理解核心思路。
import openai from typing import Dict, Any 一、Model层:大模型推理能力 class ModelLayer: def __init__(self, api_key: str): openai.api_key = api_key def reason(self, prompt: str) -> str: """模型推理:输出思考过程""" response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": prompt}] ) return response.choices[0].message.content 二、Harness层:运行管控系统(核心新增模块) class HarnessLayer: def __init__(self): self.context_memory = [] 记忆管理 self.max_context_len = 4000 上下文长度限制 self.retry_count = 3 失败重试次数 def compress_context(self, context: str) -> str: """上下文压缩:防止注意力稀释""" if len(context) > self.max_context_len: 提取关键信息,丢弃冗余内容 return context[:self.max_context_len] + "...(已压缩)" return context def validate_output(self, output: str, schema: Dict) -> bool: """输出校验:结构化约束,防止幻觉""" 检查输出是否符合预定义的JSON Schema 若不符合,触发重试机制 return True 简化示例 def check_safety(self, output: str) -> bool: """安全护栏:敏感内容过滤""" sensitive_keywords = ["密码", "银行卡号", "身份证"] for kw in sensitive_keywords: if kw in output: return False return True 三、完整的Agent:Model + Harness class HarnessAgent: def __init__(self, api_key: str): self.model = ModelLayer(api_key) self.harness = HarnessLayer() def run(self, user_input: str) -> str: Step 1: 上下文管理与压缩 self.harness.context_memory.append(user_input) context = "\n".join(self.harness.context_memory[-5:]) 只保留最近5轮 compressed_context = self.harness.compress_context(context) Step 2: 模型推理(带结构化Prompt约束) prompt = f""" 请严格遵循以下规则: 1. 仅基于提供的上下文回答问题 2. 如果不知道答案,请直接说"不知道",严禁编造 3. 输出格式:JSON {{"thinking": "思考过程", "answer": "最终答案"}} 上下文:{compressed_context} 用户问题:{user_input} """ Step 3: 执行与重试机制 for attempt in range(self.harness.retry_count): raw_output = self.model.reason(prompt) Step 4: 输出校验(结构化约束) if self.harness.validate_output(raw_output, schema=None): Step 5: 安全检查 if self.harness.check_safety(raw_output): self.harness.context_memory.append(f"AI: {raw_output}") return raw_output 重试耗尽,返回安全兜底 return '{"answer": "系统暂时无法处理该请求,请稍后重试"}' 使用示例 agent = HarnessAgent(api_key="your-api-key") response = agent.run("帮我查一下昨天的销售数据") print(response)
关键步骤标注:
Model层:大模型推理核心,提供“智能本体”能力;
Harness层:新增的工程化管控模块,包含上下文管理、输出校验、安全护栏、重试机制;
结构化Prompt约束:强制JSON输出+拒答机制,有效遏制模型幻觉-49;
重试与兜底:当Agent执行失败时自动重试,仍失败则返回安全兜底响应。
执行流程解释:用户输入 → Harness进行上下文管理 → Model推理 → Harness校验输出格式 → Harness安全检查 → 返回结果或触发重试。这个流程中的每一道“关卡”,都大大提升了Agent在生产环境中的稳定性。
五、底层原理:Harness Engineering的技术支撑
Harness Engineering之所以能够稳定放大模型能力,背后依赖以下关键技术支柱:
1. 环境隔离与沙箱(Isolation & Sandboxing) :为每个Agent实例分配独立的临时文件系统、容器或虚拟机,限制网络访问权限,防止错误操作污染生产环境-6。底层依赖Linux容器技术(Docker)和虚拟化技术。
2. 状态机与确定性编排:传统Agent框架依赖大模型隐式地生成执行步骤,不确定性高。而Harness Engineering引入状态机,通过预设的拓扑图强制约束Agent的行为边界。底层依赖LangGraph等框架对图论状态机的实现-25。
3. 结构化输出与Schema约束:通过强制Agent输出JSON格式并定义严格的输出Schema,将模型的“自由文本生成”转化为“结构化数据填充”。当模型输出不符合Schema时,校验层直接拦截并触发重试。底层依赖Pydantic等数据校验库-49。
4. 人类在环(Human-in-the-loop,HITL) :对于敏感操作(如转账、数据删除),必须由人工点击确认后方可执行。这种“AI生成→人工确认”的模式,在追求自动化的同时保留了必要的安全兜底-25。
这些技术共同构成了Harness Engineering的工程化基础——其核心设计理念不是追求模型“更强”,而是追求系统“更稳” ,正如业界总结的那样:2026年决胜关键在于工程确定性——宁停勿错-25。
六、高频面试题与参考答案
以下是2026年AI Agent岗位面试中出现频率最高的几道题,整理自最新面经复盘-51-49:
Q1:请解释Harness Engineering的核心思想。Agent = Model + Harness这个公式怎么理解?
参考答案:Harness Engineering是2026年硅谷流行的AI工程化新范式,核心思想是通过构建完整的运行环境、约束规则与反馈闭环,让AI可靠、自主地完成复杂工作。公式Agent = Model + Harness中,Model是提供推理能力的大语言模型,Harness则包含模型之外的全部代码、环境、规则、调度与验证体系。这一理念强调:AI系统的瓶颈往往不在模型本身,而在模型运行的“环境”。LangChain实测数据印证了这一观点——仅优化Harness层,在底层模型不变的情况下,任务得分可提升26%以上。
Q2:在工业场景下,如何解决大模型的“幻觉”问题?
参考答案:解决幻觉的核心在于“约束”和“接地”。工程实践中通常采用组合方案:①结构化约束(JSON Mode),强制模型输出预定义格式,不符合Schema则触发重试;②思维链引导(CoT),要求模型先输出思考过程再给出结论,使推理过程“显性化”;③知识库拒答机制,在Prompt中明确注入“不知为不知”的指令,严禁模型编造;④Few-Shot Prompting,提供3-5个标准示例让模型模仿严谨风格。四个方案结合使用,效果最佳-49。
Q3:Agent最常见的失败场景有哪些?如何解决?
参考答案:三大常见失败场景:①工具调用失败,表现为LLM生成参数格式不对或调用结果不符合预期。解决方案是增加参数校验层、失败重试机制,关键调用做人工兜底。②上下文溢出,对话轮数一多Agent就忘记之前在做什么。解决方案是做上下文压缩、定期摘要、滑动窗口控制长度。③目标漂移,Agent走着走着偏离了原始目标。解决方案是每一步都做目标对齐,定期反思总结,必要时重新规划-51。
Q4:请解释RAG、Agent、MCP三者的区别与联系。
参考答案:三者构成新一代AI应用的分层架构。RAG解决“知识不够”的问题——先检索再生成,让模型具备实时知识访问能力,但仍是被动问答型。Agent解决“行动不够”的问题——具备记忆、规划、工具调用和自我反思能力,从“说客”变成“执行者”。MCP解决“协同不够”的问题——提供统一协议标准,规范模型与外部系统的交互方式,是“AI世界的操作系统API”。三者层层递进:RAG为Agent提供知识支撑,MCP为Agent提供标准化工具接入-11。
七、总结与展望
回顾全文,我们系统拆解了硅谷AI人工助手领域2026年最硬核的技术范式——Harness Engineering:
| 知识点 | 核心要点 |
|---|---|
| 痛点 | 传统Agent能做Demo但无法稳定落地:路径坍塌、上下文稀释、缺乏纠错机制 |
| 核心公式 | Agent = Model + Harness |
| 关键概念 | RAG(知识)→ Agent(行动)→ MCP(协同)三层架构 |
| 底层技术 | 环境隔离、状态机、结构化输出、人类在环 |
| 面试重点 | 幻觉解决方案、失败场景处理、Harness设计理念 |
重点提醒:Harness Engineering的核心思维转变是从“玄学调优”走向“工程治理”,从依赖Prompt的软性约束转向系统性的工程化管控-6。这个转变对开发者提出了新的能力要求——不仅要知道如何调用大模型API,更要懂得如何为模型设计稳定、可控、可审计的运行时系统。
下一篇文章,我们将深入Harness Engineering的具体实现技术栈,包括LangGraph状态机编排、Agentic RAG的工程化实践以及模型路由策略的落地细节,敬请期待!
参考资料:Anthropic & Material 2025年12月调研报告(样本量N=500+)、LangChain官方技术博客、HashiCorp联合创始人Mitchell Hashimoto博客文章(2026年2月)、CSDN技术社区Harness Engineering系列解析